🏆 【OpenAI】TTS文本转语音Python脚本
下面是一份较全面、实用的 OpenAI 文本转语音(TTS)Python脚本示例
一、功能概览
- 作用:将输入的文字即时合成自然语音,可用于旁白、语音播报、对话型产品的发声等。
- 特点:延迟低、可多语言、提供多种预设音色(voices),可输出多种音频格式,支持流式播放。
- 典型延迟:短句通常在数百毫秒到约 1–2 秒内即可得到可播放的音频;与网络状况、模型与格式有关。
二、可用模型与差异
- gpt-4o-mini-tts(推荐默认):速度快、性价比高,适合绝大多数实时与批量场景。
- tts-1:早期通用 TTS 模型,质量与速度均衡。
- tts-1-hd:更高音质版本,适合对音频保真度要求更高、对延迟不太敏感的长内容旁白。
提示:若追求最低延迟与成本,优先 gpt-4o-mini-tts;若追求极致音质,可尝试 tts-1-hd。老的 tts-1/tts-1-hd 仍可用,但官方通常建议新项目优先采用 gpt-4o-mini-tts。
三、获取与安全使用 API Key(两种连通方式)
好的,这段文案的目标是引导用户选择“方式B”,同时显得客观、有说服力。我们可以从标题、结构、措辞和用户心理等角度进行优化。
获取 OpenAI tts-1 API KEY?看这两种方式就够了
-
方案A:官方渠道
- 特点: 流程繁琐,对网络环境有特殊要求,新手容易在注册和使用中遇到障碍。
- 适合: 熟悉海外服务注册流程,且网络条件好的资深用户。
-
方案B:国内加速 (为开发者便捷调用)
- 特点: 借助专业中转服务 (如
uiuiapi.com),连接稳定、速度快、开通简单,即刻上手。 - 适合: 追求稳定高效,希望快速开始使用的所有开发者,也是众多资深用户的选择。
- 特点: 借助专业中转服务 (如
如何调用(概览)
第一步:使用 .env 文件安全管理 API 密钥
专业的开发实践严禁将密钥、密码等敏感信息直接写入代码。最佳实践是使用环境变量来管理它们。dotenv 文件是本地开发中最流行的方式。
1. 安装 python-dotenv 库
pip install python-dotenv2. 创建 .env 文件
在您的项目根目录下(与 Python 脚本同级),创建一个名为 .env 的文件。在里面定义您的密钥。我们使用 UIUIAPI_API_KEY 这个清晰的变量名。
.env 文件内容:
# 这是环境变量文件,用于存放敏感信息
# UIUIAPI_API_KEY,输入你在uiuiapi.com或者OpenAI官方的KEY
UIUIAPI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"第二步:参数化与模型选择
一个好的脚本应该是灵活的。TTS API 通常提供多种语音模型供选择。我们可以将输入文本和语音模型作为参数,方便调用。
以 OpenAI 的 TTS 模型为例,它提供了 6 种高质量的声音:
alloy(均衡男声)echo(温暖男声)fable(沉稳男声)onyx(深沉男声)nova(活泼女声)shimmer(专业女声)
我们可以在代码中轻松切换它们:
# 要转换的文本
input_text = "你好,世界!提笔写下这句简单的问候,我带着好奇、敬意与希望。"
# 选择一个声音
selected_voice = "nova"
# 构造请求数据
data = {
"model": "tts-1",
"input": input_text,
"voice": selected_voice
}最终版本:专业级的 TTS API 调用脚本
结合以上所有最佳实践,我们得到最终的 Python 脚本。它安全、健壮、灵活且易于维护。
import os
import requests
from dotenv import load_dotenv
def generate_speech(text: str, voice: str = "alloy", output_filename: str = "speech.mp3"):
"""
调用文本转语音 API 生成音频文件。
Args:
text (str): 需要转换为语音的文本。
voice (str): 使用的语音模型名称。
output_filename (str): 输出的音频文件名。
"""
# --- 1. 加载并验证配置 ---
load_dotenv()
api_key = os.environ.get("UIUIAPI_API_KEY")
if not api_key:
raise ValueError("未找到 API 密钥。请确保在 .env 文件中正确设置了 'UIUIAPI_API_KEY'")
url = "https://sg.uiuiapi.com/v1/audio/speech"
# --- 2. 准备请求数据 ---
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
data = {
"model": "tts-1-hd",
"input": text,
"voice": voice
}
# --- 3. 发送请求并处理响应 ---
try:
print(f"正在使用声音 '{voice}' 生成语音...")
# 使用 stream=True 进行流式下载
response = requests.post(url, headers=headers, json=data, stream=True)
# 检查 HTTP 响应状态码,如果不是 2xx,则抛出异常
response.raise_for_status()
print(f"请求成功,正在将音频写入文件: {output_filename}")
# 以二进制块的方式写入文件,适用于大文件
with open(output_filename, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"音频文件已成功保存!")
except requests.exceptions.HTTPError as e:
# 捕获并打印更详细的 HTTP 错误信息(如 401, 404, 500 等)
print(f"请求失败,HTTP 错误: {e}")
print(f"响应内容: {response.text}")
except requests.exceptions.RequestException as e:
# 捕获网络或连接错误
print(f"请求失败,网络或连接错误: {e}")
except Exception as e:
# 捕获其他未知错误
print(f"发生未知错误: {e}")
if __name__ == '__main__':
# --- 使用示例 ---
long_text = "你好,世界!提笔写下这句简单的问候,我带着好奇、敬意与希望:无论经纬如何交错,我们共享同一片天空与明月。我愿倾听你每个角落的故事,珍视差异,守护脆弱的美好。"
# 使用活泼的女声 'nova'
generate_speech(long_text, voice="nova", output_filename="speech_nova.mp3")
# 使用深沉的男声 'onyx'
generate_speech("欢迎体验我们的文本转语音服务。", voice="onyx", output_filename="speech_onyx.mp3")界智通(jieagi)总结流程:
- 1.创建文件夹例如:
openaitts - 2.在
openaitts文件夹目录下创建.env文件存放秘钥。 - 3.在
openaitts文件夹目录下Python 脚本的文件,例如:openai-tts.py把Python 脚本放进你创建的文件。
完成步骤运行你的脚本文件。
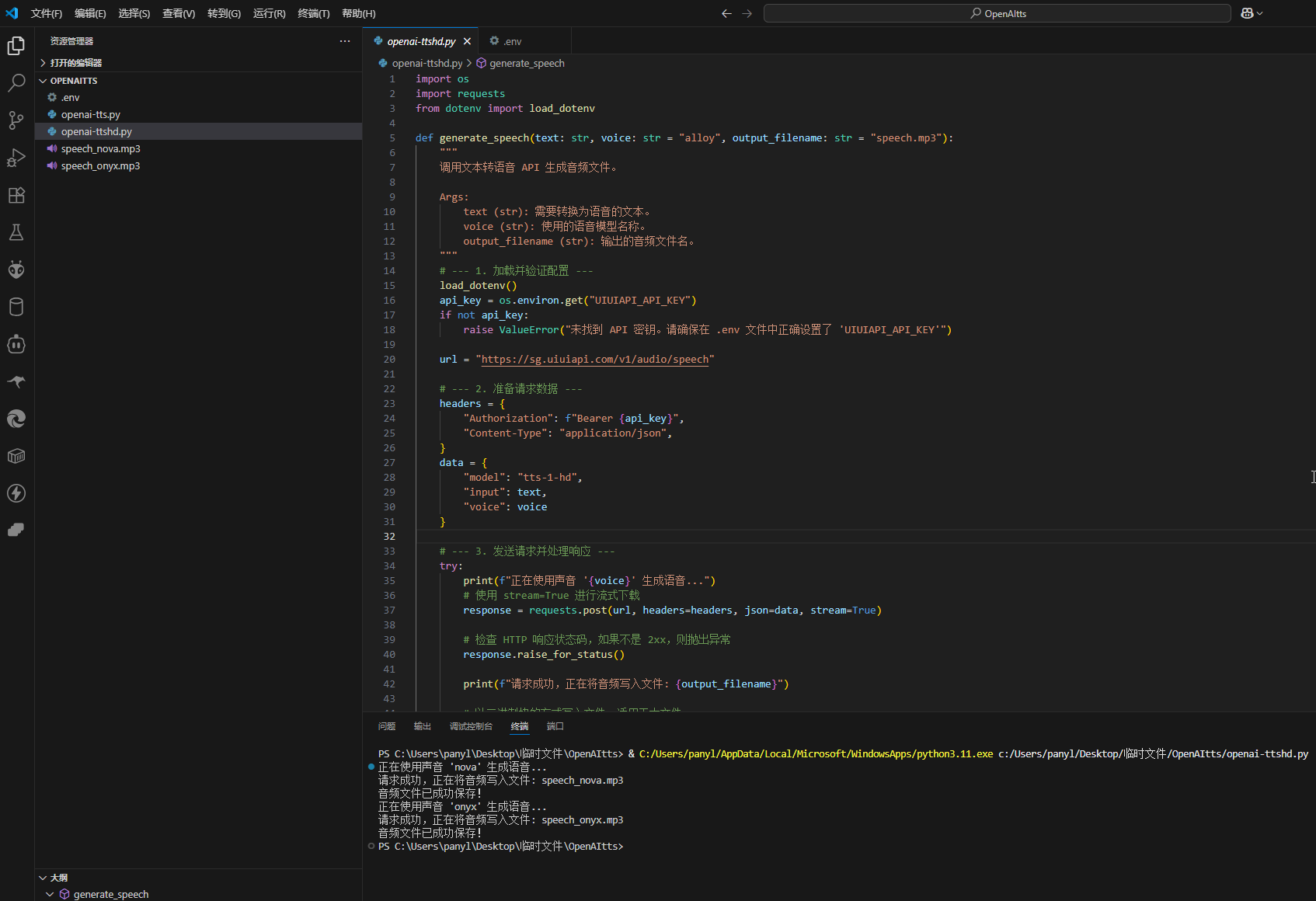
我们从一个简单的 curl 命令出发,通过引入 requests 库、使用 .env 文件保护密钥、参数化 API 调用以及构建健壮的错误处理,最终完成了一个专业级的 Python 脚本。
这个过程体现了从“能用”到“好用”的软件工程思维。您可以基于此脚本,进一步将其封装成类,或者构建一个命令行工具(CLI),甚至集成到大型 Web 应用中,为您的项目赋予强大的语音能力。